Need a Fully Managed Data Pipeline?
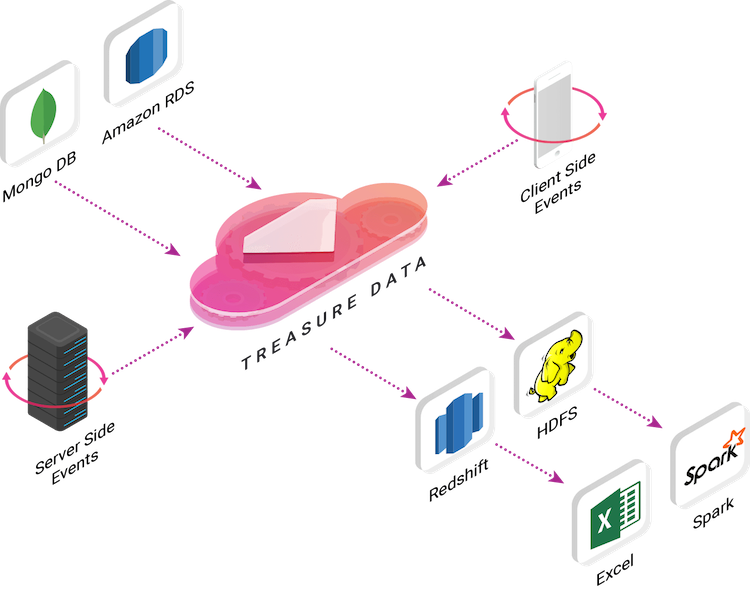 Data analysis pipelines are the software process that moves data from data sources to data destinations. Treasure Data offers a Live Data Platform which combines the best of data warehousing, includes 100+ integrations via data pipelines and scalable storage. This platform gives your organization the flexibility, scale and real-time insights to drive hyper-growth through deep customer insights.
Data analysis pipelines are the software process that moves data from data sources to data destinations. Treasure Data offers a Live Data Platform which combines the best of data warehousing, includes 100+ integrations via data pipelines and scalable storage. This platform gives your organization the flexibility, scale and real-time insights to drive hyper-growth through deep customer insights.
- Typical data pipelines have multiple data sources such as application logs, CRM systems like Salesforce, marketing tools like Marketo and Hubspot, helpdesk services like Zendesk and Intercom.
- Typical data pipelines are built by a set of scripts, often written in languages like Python and Ruby because there’s quite a bit of text processing and transformation.
- More advanced data pipelines run as workflows, using tools like DigDag and Apache Airflow.
Often data pipelines lead into data warehouses and BI tools such as Amazon Redshift and Tableau so that end users can analyze data in a single location. Rather than piecemealing a solution together from disparate parts, Live Data Management takes care of all three pieces for you.
Advantages of a Fully Managed Data Pipeline
Data pipelines unify your data across cloud infrastructure (AWS, GCP, Microsoft Azure), SaaS systems (Salesforce, Marketo, Hubspot, etc.) and internal databases (RDBMS, NoSQL, files on FTP servers, etc.) so that you can start to see the whole picture of your data, leading to more profound and actionable insights. This may work fine but may not scale scale horizontally like Treasure Data. Also the complexity of managing multiple vendors and solutions can become a bottleneck to your team’s productivity.
 Another key reason for building data pipelines is to standardize your ETL process. For example, AirBnB’s Apache Airflow grew out of their desire to simplify the process of making data available to data analysts and data scientists within AirBnb.
Another key reason for building data pipelines is to standardize your ETL process. For example, AirBnB’s Apache Airflow grew out of their desire to simplify the process of making data available to data analysts and data scientists within AirBnb.
By standardizing and simplifying the process of data collection, transformation and loading, your team becomes more productive: less troubleshooting, more automation, greater scalability. This gives your team more time for analysis and less time wrangling data.
Reasons to consider Treasure Data for Your Data Pipeline
Treasure Data is often used as a way to quickly build analytics data pipelines. Here are some of the reasons:
- Get up and running in minutes: Treasure Data’s pre-built Data Connectors mean you can connect to your data sources today without any custom coding. It also means no maintenance required to update your custom Python scripts.
- It comes with a Data Lake: Treasure Data automatically store all your data at scale so that you can combine data sources, cleanse them and transform them however you like. It also means you reduce your end-to-end latency, leading to a highly efficient data pipeline.
- It goes beyond AWS: Data pipeline services like AWS Data Pipeline assume that your entire business runs on AWS. But we know your business is more complex and will need to operate in a multi-cloud way.
- It’s Secure: Treasure Data has been voted the Best Software Company by the Cyber Defense Magazine and has received the ISO 27001 certification.
Talk with our experts
We understand that no two companies operate alike. Our professional services team can help you configure a self-managed solution that meets your budget. Our highly attentive technical support staff is always on hand whenever you need assistance.